실습에서 사용되는 데이터는 MNIST(미국 NIST에서 만든 데이터)라는 손글씨체 데이터이다.

<출처 : https://ko.wikipedia.org/wiki/MNIST_%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4>
손글씨가 있는 곳에만 그레이스케일로 28*28 Matrix=784pixel의 크기이다.
Sequential과 Model sub classing방법으로 ANN을 구현할 것이다.
Sequential이라는 방법은 직관적으로 이해하기 쉽고 Model sub classing은 복잡한 구성을 공부하기에 유리하다
다음은 이번 실습에서 사용되는 library들이다.
첫번째로 MNIST 데이터를 Load 해주고 normalize 해줄 것이다.
ANN에 사용되는 데이터는 3가지로 나뉜다. training/validation/test
그래서 train_validation_images의 개수가 몇 개인지 확인하고 그 중 80%를 train에 20%를 validation에 사용하는 코드를 작성한다.
데이터 확인을 해보자.
5라는 label과 image가 정상적으로 나오는 것을 볼 수 있다.
이번에는 데이터의 크기와 차원을 확인해볼 것이다.
이제는 학습할 model을 만들 것이다.
Sequential 방식으로 모델을 만들 것이고 맨 처음에는 Flatten layer을 만들어준다. 하나의 이미지는 28*28 픽셀로 2차원인데 이것을 1차원으로 변경하여 784개의 Input layer을 만드는 것이 Flatten()이다.
첫 번째 Hidden layer은128개의 노드 relu라는 activation function 함수를 사용할 것이다
두 번째 hidden layer은 64,노드를 사용할 것이다.
마지막 output layer은 0~9까지를 구별해줘야하기 때문에 10개의 노드를 생성했고 activation function은 softmax를 사용했다.
마지막으로 컴파일을 해야하기 때문에 손실, 최적화, 정확도를 모두 볼 수 있게 해준다.
완성된 model을 학습시킬 것이다.
train데이터를 넣어줄 것이고, batch_size 몇 개의 관측치에 대한 예측을 하고, 레이블 값과 비교를 하는지를 설정하는 파라미터이고 epochs하나의 데이터셋을 몇 번 반복 학습할지 정하는 파라미터이다. verbose는 erbose가 있으면 함수 수행시 발생하는 상세한 정보들을 표준 출력으로 자세히 내보낼 것인가를 의미한다. 0은 출력 X, 1은 자세하기 그리고 2는 함축적인 정보만을 의미한다.
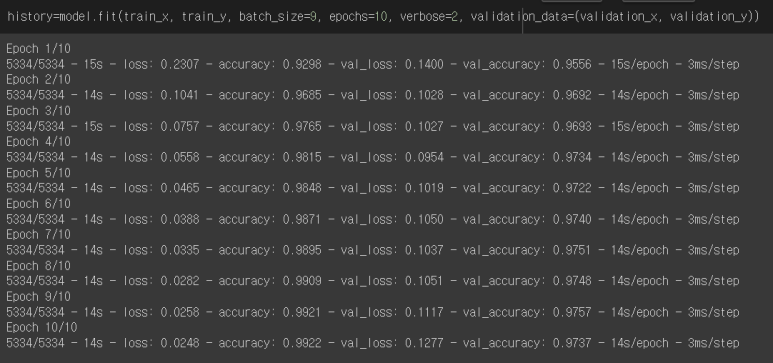
다음은 loss와 accuracy의 그래프이다.
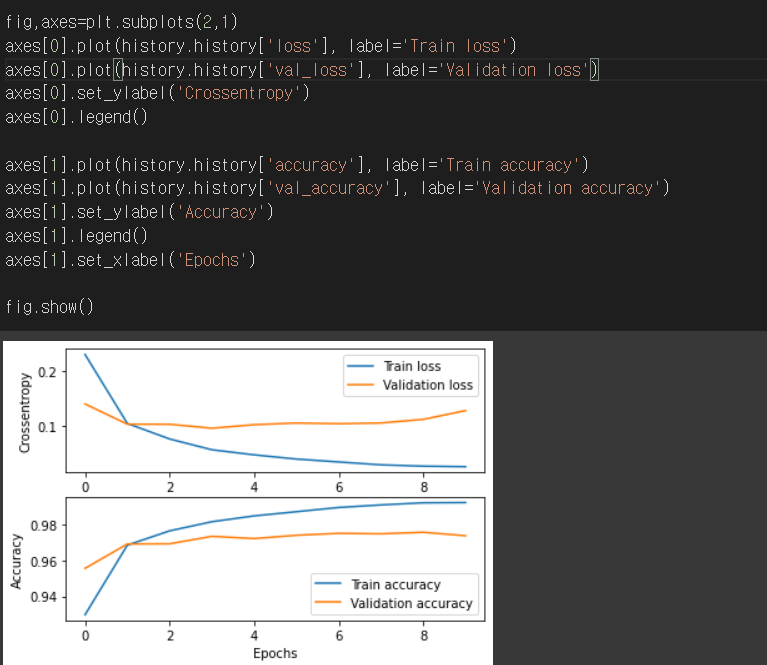
Train의 loss와 accuracy는 점점 낮아지고 높아지는 것을 볼 수 있다. validation의 그래프에서 peak가 되는 부분이 최적화된 지점이라고 볼 수 있다. 그리고 그 이후에는 overfit이 되었다고 생각할 수 있다.
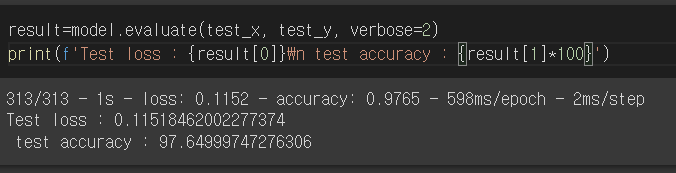
학습된 model을 다음과 같이 평가할 수 있고
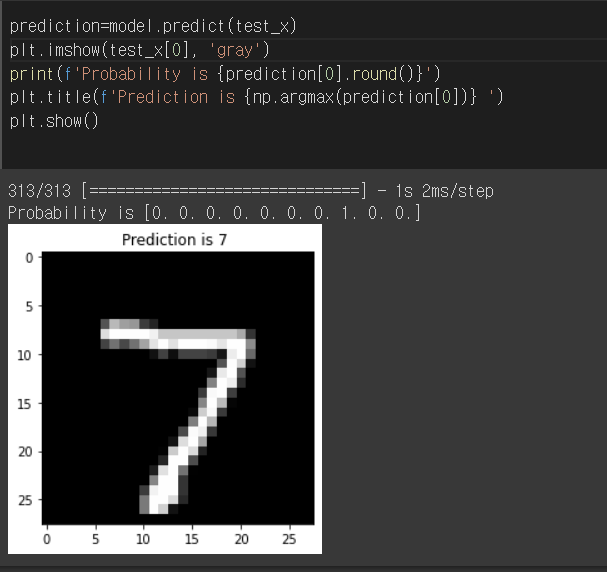
주어진 그림을 예측할 수 있다.
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]의 의미는 0~9가 될 확률을 의미한다. 여기에서는 7 그림이기 때문에 8번째 칸에 1이 있는 것이다.
오기용 교수님의 강의를 듣고 강의노트를 작성한 것이다.
'프로그래밍 > 인공지능과 여름학교' 카테고리의 다른 글
| 5주차. CNN: Principle and Architecture (0) | 2022.12.31 |
|---|---|
| 4주차. CNN : convolution (0) | 2022.12.29 |
| 2주차. ANN Optimization (0) | 2022.12.27 |
| 1주차. ANN_from Perceptron to MLP (1) | 2022.12.27 |



